|
|
|
|
|
|
|
|
|
|
ICCV 2021

|

|

|

|

|

|
|
|
|
|
|
|
|

HeadGAN method performs one-shot reenactment (b), by fully transferring the facial expressions and head pose from a driving frame to a reference image. When the driving and reference identities coincide (c), it can be used for facial video compression and reconstruction. In addition, HeadGAN can be applied to facial expression editing (d), novel view synthesis (e) and face frontalisation (f). Note that the original reference image (a) has not been seen during training.
Method
We propose a GAN-based system that conditions synthesis on 3D face representations, which can be extracted from a driving video and adapted to the facial geometry of the reference image. We capitalise on prior knowledge of expression and identity disentanglement, enclosed within 3D Morphable Models (3DMMs). As a pre-processing step, first we reconstruct and then render the 3D face from the reference image, as well as the driving frame, after adapting the identity parameters. We further improve mouth movements, by utilising audio features as a complementary input to HeadGAN.
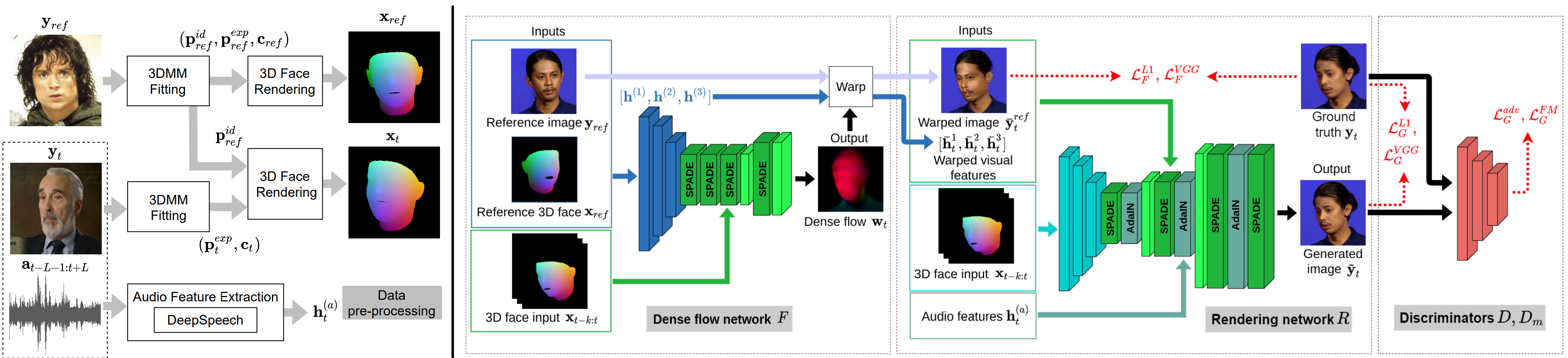
Our Generator consists of two sub-networks: a dense flow network F and a rendering network R. The dense flow network F computes a flow field for warping the reference image and features, according to the 3D face input. Then, the rendering network R uses this visual information along with the audio features in order to translate the 3D face input into a photo-realistic image of the source.
Supported Tasks
Reenactment
Reconstruction
3D face modeling with 3DMMs makes HeadGAN very efficient for video conferencing applications. It enables a "sender" to efficiently compress a driving frame, in the form of expression and camera parameters, with a total of 35 floating point values. Then, these parameters can be used by a ”receiver” to render the 3D face and use the Generator to reconstruct the driving frame. The reference image needs to be sent once in the beginning of the session.
Expression and Pose Editting Tool
Our model can be further used as an image editing tool. Given any source image and its shape and camera parameters, first we render the corresponding 3D face representation. Then, we re-adjust the expression or camera parameters manually and render a pseudodriving 3D face, reflecting the adjusted parameters.
Citation
In case you find this work useful to your research, please cite our paper.
@InProceedings{Doukas_2021_ICCV,
author = {Doukas, Michail Christos and Zafeiriou, Stefanos and Sharmanska, Viktoriia},
title = {HeadGAN: One-Shot Neural Head Synthesis and Editing},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {14398-14407}
}